One more post on writing generic algorithms. Let’s take a non-trivial non-generic algorithm and write a generic version. We’ll port a Java implementation of merge sort, and also look at some other interesting things we might do to some Java code when converting it to Swift.
Why bother with a merge sort? Well, the standard library comes with a very efficient in-place sort, based on the introsort, but it’s not a stable sort – that is, two otherwise equal entries aren’t guaranteed to stay in the same order, something that is often expected in things like grids that sort when you click a column header.
To start off, here is a Java version of a bottom-up merge sort, taken from Sedgewick, in all its Java-y C-for-loop-y zero-based-integer-index-y glory. Check out the vertigo-inducing braceless for loops!
public class Merge {
private static Comparable[] aux;
private static void merge(Comparable[] a, int lo, int mid, int hi) {
int i = lo, j = mid+1;
for (int k = lo; k <= hi; k++)
aux[k] = a[k];
for (int k = lo; k <= hi; k++)
if (i > mid)
a[k] = aux[j++];
else if (j > hi)
a[k] = aux[i++];
else if (aux[j].compareTo(aux[i]) < 0)
a[k] = aux[j++];
else
a[k] = aux[i++];
}
public static void sort(Comparable[] a) {
int N = a.length;
aux = new Comparable[N];
for (int sz = 1; sz < N; sz = sz+sz)
for (int lo = 0; lo < N-sz; lo += sz+sz)
merge(a, lo, lo+sz-1, Math.min(lo+sz+sz-1, N-1));
}
}
This is generic on the array’s contents, but not on the container (not that you couldn’t write a container-generic version in Java too, but this isn’t a Java blog, I get quite enough Java in my day job thanks).
A good first step to turn this into a generic Swift algorithm would be just to port it to Array first. But even this presents some interesting problems – it’s not just a straight port, despite Java and Swift’s common ancestry. So let’s port it to Swift and make it more Swift-like at the same time, while keeping the algorithm broadly similar (speaking of which, yes, I know you can do it recursively but we’ll stick with the iterative version).
A first step would be ditching the very Java-esque practice of creating a class just to wrap some static methods. This passes for normal in the kingdom of nouns, but in Swift this would be more suited to an extension, with self taking the place of the a parameter:
extension Array {
// really this ought to be marked rethrows but
// let’s ignore that to keep things simple...
public mutating func stableSortInPlace(
isOrderedBefore: (Element,Element)->Bool
) {
let N = self.count
// etc.
}
}
Why not write a version for Array where Element: Comparable? Well, Comparable conforms to Equatable, which has the following stern warning in its comment:
Equality implies substitutability. When x == y, x and y are interchangeable in any code that only depends on their values.
When needing a stable sort, the whole point is that you’re only comparing part of the values – you sort by last name, while wanting rows with the same last name to stay in the same order. Obviously that means that the two values you’re comparing are not substitutable. So it probably only makes sense to implement this sort with a comparator function. Never, ever, conform to Comparable by comparing only part of the visible properties of your type.
The first problem we face is that temporary storage array aux. Well, two problems really. The Java version does something that would be pretty monstrous in anything other than a textbook example – it uses a static variable. This would be fine for single-threaded code but if ever you used this same function simultaneously from two threads (even on two different arrays) then kerplowie. Brings back fond memories of debugging production problems from someone calling strtok from multiple threads. Sorry, did I say fond? I meant traumatic.
Anyway, even if you wanted to do it with a static property, you couldn’t, because you can’t add static variables to generic types in Swift. (if you wonder why – think about what would happen if there were a static property on Array – should there be just one static variable for both [Int] and [String], or two different ones?)
So we need another way. We could just declare a new array inside merge every time, but that would allocate fresh array storage on every call, which would be horribly inefficient.
Alternatively, you could create the array once in the sort function, just like in the Java version, but then pass it as an argument into the merge function. This would ugly up the code a bit. But more importantly, it wouldn’t work with Swift arrays, because they are value types. If you created an array in sort then passed it into merge, it could be copied(-on-write), not re-used, which would be even worse than declaring a new one.
(If you are thinking inout or var is the solution, you’re also out of luck there. Despite what that call-site ampersand might imply, inout in Swift is not pass-by-reference, but rather pass-by-value-then-copy-back. var is similarly no help – it’s just shorthand for declaring a second mutable variable and assigning it the value of the parameter. Plus var is going away soon, probably partly because it caused this kind of confusion. UPDATE: per @jckarter, the inout situation may not be so clear-cut and ought to work in this case)
You could use reference-type storage, like NSArray, instead. Or you could allocate some memory yourself using UnsafeMutablePointer. Or use a Box class to wrap an array in a reference type. But here’s a perhaps neater alternative – declare merge as an inner function, and make it a closure that captures a local array variable:
extension Array {
public mutating func stableSortInPlace(
isOrderedBefore: (Element,Element)->Bool
) {
let N = self.count
// declare a local aux variable
var aux: [Element] = []
// make sure it has enough space
aux.reserveCapacity(self.count)
// local merge function that can operate on (capture) self
func merge(lo: Int, _ mid: Int, _ hi: Int) {
// merge captures the aux variable _by ref_
// we can now use aux to merge self
}
for etc. {
merge(etc.)
}
}
}
When a function closes over a variable, it captures it by reference. This means that merge and the outer sorting function will share the same instance, exactly what we want. Unlike the static approach, there’s no risk that a second call will use the same storage – aux is still local to the call to sort, and two different calls will use two different local storage arrays, and so will their inner variables. The one downside of this is we wouldn’t be able to expose our merge function publicly, even though it could be a useful algorithm in its own right.
By the way, even though we declared merge with func, it is still a closure – don’t conflate the term closure (functions plus captured environment), with closure expressions (the Swift term for the shorthand syntax for writing anonymous functions). Local functions declared with func are just as closurey as closure expressions.
OK that solves that problem, but there’s a second issue. In the Java version, the array is declared to be a given fixed size:
aux = new Comparable[N];
and then the merge function just plunges in and uses bits of it:
for (int k = lo; k <= hi; k++)
aux[k] = a[k];
Here’s another place where both Java and Swift start from their common ancestor, but then Java zigs while Swift zags. In C, you declare a variable, and then you can immediately read from it without giving it a value. Everyone agrees that this is all very horrible and monstrous, but to not have that you have to choose a path – give everything a default value, like in Java, or ban reading until you’ve written, like in Swift.
There are maybe performance reasons why Swift’s choice is better. But really, it was forced by other factors. In Java, everything is either a primitive type, or a reference. With such a limited set of types it’s reasonable to give everything a default value – either zero, empty, or null. But Swift isn’t so simple. It doesn’t even really have “primitive” types – even Int is a struct. And while it has references, they aren’t always nullable. So everything having a default isn’t really an option.
So it follows that in Swift you can’t have an Array where you just declare it to be a given size then plunge in getting and setting elements at arbitrary indices. I mean, you could write an array that worked like that, but then you’d have to track internally when values for given index had been set or not. So instead, to make an array have n elements, you have to put n in. You can do that easily with Array(count: n, repeatedValue: ???), but for our purposes, what would you put as the value? Element is completely generic, you don’t know anything about it, so there’s no reasonable default.
One solution is to use an array of Optional. That way, you can set them all to nil. Probably this would be one of those rare legit uses of an implicitly-unwrapped optional – where you can prove that at the time you use the optional that it wil never be nil, so there’s no harm unwrapping it implicitly. In fact, you’d like it to assert if you ever unwrapped a nil, as this would mean there was something horribly wrong with your logic.
extension Array {
public mutating func stableSortInPlace(
isOrderedBefore: (Element,Element)->Bool
) {
let N = self.count
var aux = Array<Element!>(count: N, repeatedValue: nil)
func merge(lo: Int, _ mid: Int, _ hi: Int) {
var i = lo, j = mid+1
for var k = lo; k <= hi; k++ {
aux[k] = self[k]
}
for var k = lo; k <= hi; k++ {
if i > mid { self[k] = aux[j++] }
else if j > hi { self[k] = aux[i++] }
else if isOrderedBefore(aux[j],aux[i])
{ self[k] = aux[j++] }
else { self[k] = aux[i++] }
}
}
for var sz = 1; sz < N; sz = sz+sz {
for var lo = 0; lo < N-sz; lo += sz+sz {
merge(lo, lo+sz-1, min(lo+sz+sz-1, N-1))
}
}
}
}
This now works, and is pretty much like the Java version. But implicitly-unwrapped optionals are a bit unpleasant, and anyone unhappy about the merge sort’s linear space requirements might blanche at the extra bits they take up. And the rest isn’t very Swift-y. Those for loops and ++ are not long for this world, and it’ll bit a bit painful to translate this into a fully generic function.
Instead, lets:
- Flip it around and have the merge logic copy into the
auxarray, then copy back intoself, usingappend, removing the need to size it up at the beginning. - At the same time, we can switch the
forfor awhile, and ditch the++ - Switch from closed ranges (up-to-and-including
hi) to half-open ranges (up-to but not includinghi) since this is more the Swift convention (and will be easier in the next part) - Use
appendContentsOfandreplaceRangeinstead of hand-rolled loop-and-assign
which gives us this merge function:
// ditch the optionals
var aux: [Element] = []
// make sure aux has enough memory to store a fully copy
// (note, does _not_ actually increase aux.count)
aux.reserveCapacity(N)
func merge(lo: Int, _ mid: Int, _ hi: Int) {
// wipe aux, but keep the memory buffer
// at full size each time around
aux.removeAll(keepCapacity: true)
var i = lo, j = mid
while i < mid && j < hi {
// append the lesser of either element
if isOrderedBefore(self[j],self[i]) {
aux.append(self[j])
j += 1
}
else {
aux.append(self[i])
i += 1
}
}
// then append the stragglers
// (one of the next 2 lines will be a no-op)
aux.appendContentsOf(self[i..<mid])
aux.appendContentsOf(self[j..<hi])
// then copy the sorted temp storage back into self
self.replaceRange(lo..<hi, with: aux)
}
Finally, we need to do the same for the sorting for loops:
for var sz = 1; sz < N; sz = sz+sz {
for var lo = 0; lo < N-sz; lo += sz+sz {
merge(lo, lo+sz-1, min(lo+sz+sz-1, N-1))
}
}
That outer for is kinda sneaky, since it’s doubling sz each time around the loop, so that needs a while rather than a stride. The inner one is a lot simpler though, it’s just striding over the array by a constant sz*2 each time. Moving to half-open rather than closed ranges makes this a whole lot easier, since it gets rid of all the annoying -1s littered about:
var sz = 1
while sz < N {
for lo in 0.stride(to: N-sz, by: sz*2) {
merge(lo, lo+sz, min(lo+sz*2, N))
}
sz *= 2
}
This leaves us with a final version, Swiftified if not yet generic. It’s a little more verbose than the original Java, but mainly because of the loss of the compact for and ++ notation, and hopefully a bit more readable for it:
extension Array {
public mutating func stableSortInPlace(
isOrderedBefore: (Element,Element)->Bool
) {
let N = self.count
var aux: [Element] = []
aux.reserveCapacity(N)
func merge(lo: Int, _ mid: Int, _ hi: Int) {
aux.removeAll(keepCapacity: true)
var i = lo, j = mid
while i < mid && j < hi {
if isOrderedBefore(self[j],self[i]) {
aux.append(self[j])
j += 1
}
else {
aux.append(self[i])
i += 1
}
}
aux.appendContentsOf(self[i..<mid])
aux.appendContentsOf(self[j..<hi])
self.replaceRange(lo..<hi, with: aux)
}
var sz = 1
while sz < N {
for lo in 0.stride(to: N-sz, by: sz*2) {
merge(lo, lo+sz, min(lo+sz*2, N))
}
sz *= 2
}
}
}
Making it work on any random-access collection
OK, now to make it generic. A lot of that rework from before will make this easier.
First, to make this an extension of a protocol instead of protocol instead of Array. We actually used self.replaceRange, so let’s make it an extension of RangeReplaceableCollectionType (maybe a bit of an overconstraint – you could do without it and just make do with MutableCollectionType, but let’s ignore that). Plus the where clauses. We know the index needs to be random-access. We also rely on slicing, so per the previous article on this topic, we need to require SubSequence contains the same elements as the sequence:
extension RangeReplaceableCollectionType
where
Index: RandomAccessIndexType,
SubSequence.Generator.Element == Generator.Element {
Doing this in Xcode will now show you all the places where you are relying on assumptions that no longer hold now you aren’t just writing against Array (though, more spring up as you fix these…)
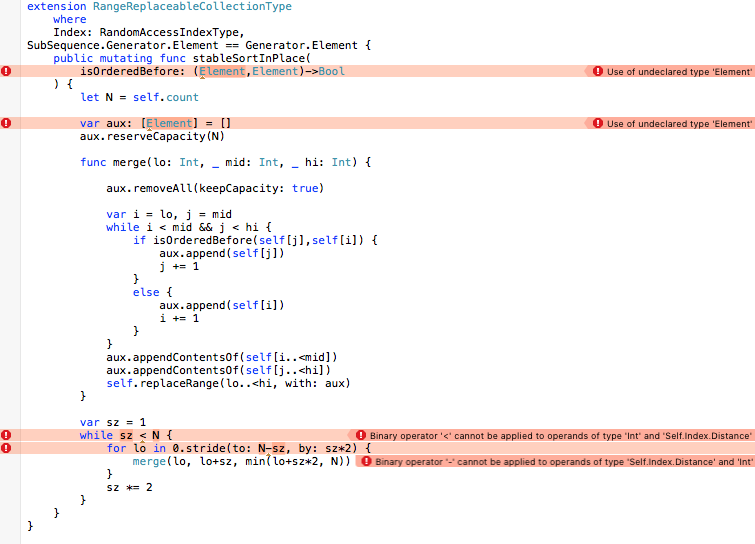
Easy ones first. Generator.Element instead of just Element:
public mutating func stableSortInPlace(
isOrderedBefore: (Generator.Element,Generator.Element)->Bool
) {
let N = self.count
var aux: [Generator.Element] = []
Next, aux.reserveCapacity. We want to reserve the number of elements, but that comes (via aux.count) in the form of a Self.Distance. Remember, distances are always integers, but they might not be Int. We have to use numericCast to fix this:
aux.reserveCapacity(numericCast(N))
I admit, I haven’t quite got my head around whether this is an OK thing to do or not. For almost every reasonable circumstance, this will be a no-op, since Distance will be an Int. If for some reason you were using a class that used a smaller Distance, it will upconvert it. There’s a slim chance that Distance could be bigger than an Int – say if you’re on 32-bit platform but using a collection that used an explicit 64-bit index? Or maybe some giant virtual collection that used a BigInt? But for now I shall ignore these possibilities with reckless abandon.
So long as the where constraints above, the merge function is easy. You just make lo, mid, and hi an Index instead of an Int:
func merge(lo: Index, _ mid: Index, _ hi: Index) {
// the rest is the same
}
OK now for the interesting bit, the sorting loops:
var sz = 1
while sz < N {
for lo in 0.stride(to: N-sz, by: sz*2) {
merge(lo, lo+sz, min(lo+sz*2, N))
}
sz *= 2
}
The trick is, knowing which ones are indices, and which ones are distances (by which indices will be advanced).
sz is a distance. It’s the length by which each pass strides through the collection performing the merge, and which doubles each time around (giving the algorithm its linearithmic performance characteristic). To make that explicit, we need to annotate it with a type (otherwise it’s going to default to being an Int):
var sz: Index.Distance = 1
We already established N is the size of the collection and is also a distance, so this is fine (you can compare two distances, and you can double distances):
while sz < N {
// inner for stride
sz *= 2
}
Finally, the inner stride:
for lo in 0.stride(to: N-sz, by: sz*2) {
merge(lo, lo+sz, min(lo+sz*2, N))
}
lo is an Index – that’s what we pass in to merge as lo. The calculated mid and hi are indices too. When you see 0 as an index, that really means startIndex so we can substitute that.
The only other tricky part is N. With zero-based integer indices, N could mean two things: the length of the collection, or the end of the collection (i.e. startIndex.advancedBy(N)). Here, in this inner loop, it means the latter. So N-sz means “back from the end by sz“.
Similarly min(lo+sz*2, N) means “add sz*2 to lo, or endIndex if that goes past the end”. So you could write min(lo+sz*2, N). But there’s already a function for “go this far, but not past this point”. advancedBy is overloaded with a version that takes a limit: argument. So instead, you can write this as lo.advancedBy(sz*2,limit: endIndex)). This is arguably more correct as well, since it could be an error to add a distance to an index to take it past the end of the collection (like with String indices).
So we rewrite the inner loop as:
for lo in startIndex.stride(to: endIndex-sz, by: sz*2) {
merge(lo, lo+sz, lo.advancedBy(sz*2,limit: endIndex))
}
Again, if you’re doing this in Xcode, the compiler will help you along (for example, it will complain if you’re trying to take the minimum of an index and a distance, since you can’t do that, which is a hint you need an index instead of a distance).
One final gotcha. After you make all these changes and you’re sure everything is correct, the stride still won’t compile. We need one more constraint on the protocol: Index.Distance == Index.Stride. Yes, this should always be the case (that’s the whole point of making random-access indices strideable – so you can stride by Distance), but you still need to make it explicit.
After all this we finally have a fully generic random-access in-place merge sort:
extension RangeReplaceableCollectionType
where
Index: RandomAccessIndexType,
SubSequence.Generator.Element == Generator.Element,
Index.Distance == Index.Stride {
public mutating func stableSortInPlace(
isOrderedBefore: (Generator.Element,Generator.Element)->Bool
) {
let N = self.count
var aux: [Generator.Element] = []
aux.reserveCapacity(numericCast(N))
func merge(lo: Index, _ mid: Index, _ hi: Index) {
aux.removeAll(keepCapacity: true)
var i = lo, j = mid
while i < mid && j < hi {
if isOrderedBefore(self[j],self[i]) {
aux.append(self[j])
j += 1
}
else {
aux.append(self[i])
i += 1
}
}
aux.appendContentsOf(self[i..<mid])
aux.appendContentsOf(self[j..<hi])
self.replaceRange(lo..<hi, with: aux)
}
var sz: Index.Distance = 1
while sz < N {
for lo in startIndex.stride(to: endIndex-sz, by: sz*2) {
merge(lo, lo+sz, lo.advancedBy(sz*2,limit: endIndex))
}
sz *= 2
}
}
}
I’d suggest you try it out on a mutable random-access collection that doesn’t have integer indices. Except, uh, there aren’t any. There are random-access collections without integer indices – reverse collections for example. Or (with a bit of extension-bullying) String.UTF16View. But unfortunately these aren’t mutable! So perhaps I’ve just totally wasted your time. But it was fun, right?
OK so there’s also a much more important benefit to this – it no longer relies on the index starting from zero. Yes, we could have done this for CollectionType where Index: IntegerType, but that would probably have been harder, since the compiler would not have helped as much when we made invalid assumptions. The 0 instead of startIndex might be easy to catch, but assumptions about when N means endIndx vs when N means self.count are much tricker.
Now that we’ve made this change, you can now apply the algorithm in-place to subranges, such as:
var a = Array(1...5) a[1..<4].stableSortInPlace(>) // a = [1,4,3,2,5]
And finally, just to check it really is still a stable sort after all this futzing around (that property is easy to break if you make innocent-seeming changes to the order of your i and j comparisons – something I learned the hard way, forgot, then remembered the hard way during the course of writing this…)
var pairs = [
(2,1), (2,2),
(3,1), (3,2),
(1,1), (1,2),
(1,3),(2,3),(3,3)
]
pairs.stableSortInPlace { $0.0 < $1.0 }
print(pairs.map { $0.1 })
// if sort is stable, ought to print
// [1, 2, 3, 1, 2, 3, 1, 2, 3]



